What Even is Data Science?
Some Popular Definitions
As a Data Scientist, the question ‘What is Data Science?’ is one that, naturally, I find to be pretty important. Wikipedia defines Data Science as follows:
Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from noisy, structured and unstructured data, and apply knowledge and actionable insights from data across a broad range of application domains.
Now this on the surface, seems like a reasonably good definition, that maybe it loses a bit of accuracy in the minutiae, as all explanations do, but it gets the point across. Now, even setting aside that Wikipedia should never be considered useful for than a cursory glance or refresher, what happens if we dig just a little deeper?
According to IBM Data Science is:
… a multidisciplinary approach to extracting actionable insights from the large and ever-increasing volumes of data collected and created by today’s organizations. Data science encompasses preparing data for analysis and processing, performing advanced data analysis, and presenting the results to reveal patterns and enable stakeholders to draw informed conclusions.
Although IBM’s definition, is, perhaps somewhat reasonably, rather corporate given the use of terms like ‘stakeholders’, it too doesn’t seem rather objectionable on the face of it.
What about Coursera?
Data science has critical applications across most industries, and is one of the most in-demand careers in computer science. Data scientists are the detectives of the big data era, responsible for unearthing valuable data insights through analysis of massive datasets. And just like a detective is responsible for finding clues, interpreting them, and ultimately arguing their case in court, the field of data science encompasses the entire data life cycle.
While in some sense that is true, it is certainly partaking in the art of speaking without actually saying anything, something I vehemently detest. Thanks guys.
Ok, we’ll try one more, what about UC Berkeley?
Data science continues to evolve as one of the most promising and in-demand career paths for skilled professionals. Today, successful data professionals understand that they must advance past the traditional skills of analyzing large amounts of data, data mining, and programming skills. In order to uncover useful intelligence for their organizations, data scientists must master the full spectrum of the data science life cycle and possess a level of flexibility and understanding to maximize returns at each phase of the process.
Certainly we see UC Berkeley is able to describe some of the traits a Data Scientist should have, there is one small problem, and that is that they list traits that really any respectable scientist should have regardless of discipline A little later down their page, they show an image of what they call ‘The data science life cycle.’
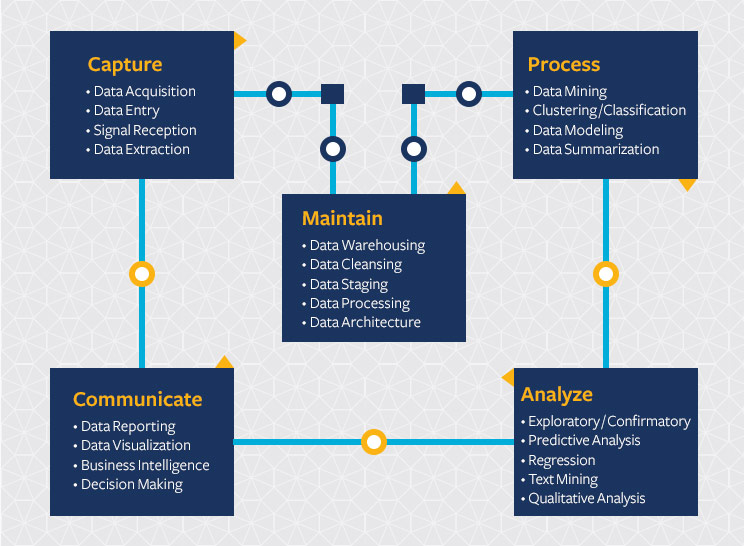
Here’s the thing, all scientists have to capture (i.e. collect), process, analyse, communicate and maintain data. The idea that other branches of science, such as Physics or Psychology don’t do this, is frankly laughable. The only real difference with a distinction is the volume of data that they collect.
What should be pointed out however, is that unlike probably any other discipline of science, Data Science has data native to its discipline. What do I mean by this? Well consider for a second a Chemist, for the sake of argument, we’ll say they are an inorganic chemist. When the inorganic chemist partakes in his discipline, he formulates hypotheses, within the confines of inorganic chemistry, then he performs an experiment and obtains data, again within the confines inorganic chemistry, and finally draws conclusions within the confines of inorganic chemistry. This is true for every discipline of science, except data science.
A New Definition
I therefore put forward, the following definition as to what Data Science is.
Data Science is the discipline where the foundations of computer science and statistical inference are combined with one or more other disciplines, to provide novel, reproducible, inductive insights.
Wait, so you’re saying that data scientists require first hand knowledge of at least three distinct disciplines to be able to do their job?
The answer is yes, with no hint of irony, yes. Let’s break down exactly what data science is, so that can see just why this is the case.
First, one of the most important part of what data scientists are expected to do, is to process large amounts of data (sometimes structred, sometimes not) and do so in a way that is reproducible. To process large amounts of data in a way that is reproducible should be very obviously seen for what it is, a programming task, which is a subset of computer science.
Second, the output is primarily in one of two categories; It is either some form statistical test or analysis (hypothesis testing, analysis of variance, etc), or a machine learning model (such as a neural network). For anyone with even a cursory familiarity of logic and statistics (or machine learning), it should be quite readily apparent that this is an inductive enterprise. For those who are not suffice it to say that reasoning is inductive, if it takes information from a specific case (i.e. a sample) and attempts to generalise any structure to the general case (i.e. the population).
Finally, that data has to come from somewhere doesn’t it? The knowledge of statistics and computer science doesn’t just pop data into existence (though that would certainly make my life easier!), and that data will come from some other field with it’s own assumptions, methods and required knowledge.